
〜AIに手伝ってもらったロングライド予測ツール開発記 2〜
前回は、「日没前に帰るには何時に出発すればいいのか」を知るために、自分用のロングライド予測ツールを作ろうと思った経緯を書きました。
STRAVAで距離や獲得標高はわかりますが、自分がそのルートを走った時に、休憩や信号待ち、後半の疲労まで含めて何時間かかるのかはよくわかりません。そこで、自分の過去走行データを使って、もう少し自分に即した予測ができないだろうか、と考えたわけです。
今回は、ChatGPTに相談しながら実際に試作を始めていきます。
過去の走行データを分析し、STRAVAで作ったGPXルートから予測時間を出し、補給プランやステムシートのようなものを作る。そうやって試行錯誤しながら進めていったら、次から次へと分析スクリプトやデータが増殖し、だんだん収拾がつかなくなったというお話しです。
まずは予測移動時間を出したい
最初にやりたかったのは、STRAVAで作ったルートを読み込ませて、自分が走った場合にどのくらい時間がかかりそうかを出すことでした。
STRAVAから書き出したGPXファイルには、ルート上の位置や標高などの情報が入っています。詳しい人には当たり前なのだと思いますが、こちらとしては、GPXというファイルに何が入っているのかもよく知りません。
そこで、ChatGPTに「STRAVAのGPXから距離や勾配を読み取り、自分の過去データをもとに予測時間を出したい」と相談しました。
すると、GPXを読み取るためのPythonスクリプトが出てきます。
言われた通りにファイルを置いて実行してみると、CSVファイルが作られました。中には、距離や勾配、予測速度、到達時刻のような数字が並んでいます。
おお、なんか出た。
この時点では、それが正しい予測なのかどうかもよくわかっていません。ただ、自分ではプログラムを書けないのに、相談して言われた通りに進めたら、それらしい数字が出てきたことには少し感動しました。
勾配ごとの速度から予測する
予測の基本になったのは、自分の過去ログから見た勾配ごとの速度です。
平坦ではどのくらいの速度で走っているのか。緩い登りではどのくらい落ちるのか。5%を超える登りならどうか。下りではどのくらい速度が出ているのか。
過去の走行ログを分析すれば、自分がそれぞれの勾配でどのくらいの速度になりやすいかは、ある程度見えてきます。
新しく走るルートを細かい区間に分け、それぞれの勾配に応じた自分の予測速度を当てはめる。それを積み上げていけば、ルート全体の移動時間を計算できる、という考え方です。
もちろん、実際の速度は路面や交通量、信号、風などにも左右されます。それでも、一般的な平均値ではなく、自分の過去データを基準にすることで、少なくとも自分なりの予測には近づきそうです。
そこで、過去データから勾配と速度の関係を分析するスクリプトを作り、それを使ってGPXルートの予測を出してみることになりました。

とりあえず数字は出た
試しに伊豆イチのルートを読み込ませた時には、こんな結果が出ました。
Route: 260508_伊豆イチ.gpx
Route points: 47447
Distance: 274.1 km
Predicted moving time: 13.27 h
Predicted avg speed: 20.7 km/h
距離274.1kmに対して、予測移動時間は13.27時間。予測平均速度は20.7km/h。
数字としてはそれっぽい。
距離と獲得標高を眺めて頭の中で考えるよりも、だいぶ具体的です。少なくとも「このルートを走ったら、とんでもなく遅くなるのか、それなりに走れそうなのか」という大まかな感触は掴めそうでした。
ただし、ここで出ているのは移動時間です。
信号待ちやコンビニ休憩、食事休憩、写真を撮るために止まった時間などは入っていません。
僕が本当に知りたいのは、出発してから帰着するまでのグロス時間です。自宅発着の場合もあれば、輪行先の駅などを拠点にする場合もありますが、移動時間が13時間だからといって、出発から13時間後に戻ってこられるわけではありません。
では、休憩込みでは何時間になるのか。
ここから少し話がややこしくなります。
休憩時間は予測なのか、提案なのか
ロングライドの休憩時間は、その日の状況によってかなり変わります。
コンビニでドリンクを買うだけなら数分で済みますが、食事をすれば長くなります。暑ければ日陰で休みたくなりますし、景色が良ければ写真も撮りたい。特に理由はなくても、カフェを見つけて吸い込まれる場合もあります。
そう考えると、休憩時間を正確に当てるのはかなり難しい。
そこで、休憩は予測するというより、最初に休憩パターンを決めてグロス時間を計算する方が現実的なのではないか、という話になりました。
たとえば、1時間ごとに10分休憩する。2時間ごとに短い休憩を入れ、4時間ごとに少し長めの休憩を取る。あるいは、コンビニのある場所や長い登坂の前を休憩地点として提案する。
実際のライドで予定通りに休む必要はありませんが、こうした休憩プランを置いておけば、移動時間からグロス時間を見積もることはできます。
予測時間が出たことで一歩前進したと思ったら、今度は「休憩をどう扱うか」という問題が出てきました。
せっかくなら補給プランも欲しい
休憩のことを考え始めると、当然ながら補給のことも気になってきます。
10時間以上走るなら、どこで何を食べるかはかなり重要です。補給が遅れて後半に大きく崩れたら、日没前に帰るための予測も意味がなくなってしまいます。
最初は、1時間ごとの予想到達地点がわかれば十分だと思っていました。しかし、時間ごとの地点が出るなら、そこに補給の目安も載せられるのではないか、と考えてしまいます。
1時間あたり何kcalくらい摂ればいいのか。長い登坂に入る前に何か食べておくべきか。コンビニがしばらくない区間へ入る前に、水や補給食をどれくらい買っておけばいいのか。
そこまで出せれば、単なる所要時間の予測表ではなく、ライド中に使える計画表になりそうです。
そこで、補給プランも作り始めました。

予測CSVに加えて、補給プラン、心拍分析、勾配と心拍の分析、ステムシート用のPDF、グラフや表など、出力されるものが徐々に増えていきます。
何かを思いついて「これも出せない?」と聞けば、ChatGPTはだいたい何かしら作ってくれます。
便利なのを良いことに調子に乗っていたら、だんだん困った状況になり始めました。
分析スクリプトが増殖する
AIに相談しながら作っていると、「こうしたい」という希望に応じて、次々に新しいスクリプトが出てきます。
GPXを読むもの、勾配別速度モデルを作るもの、補給プランを作るもの、PDFにするもの、グラフを出すもの。
最初は、それぞれに役割があるので便利に見えます。
ところが、修正を重ねていくうちに、だんだん自分でもわからなくなってきました。
今使っているスクリプトはどれなのか。これは古いものなのか、修正版なのか。このCSVは何から出力されたものなのか。このPDFを作った時には、どんな設定を使っていたのか。
ChatGPTから新しいスクリプトを受け取るたびに保存していましたが、どれが現在の正解なのかを管理する仕組みはありません。
途中で修正を頼んだ結果、以前に作ったものへ逆戻りしているように見えることすらありました。
実際、チャットの中でも僕は、「なんか、だいぶ前に作ってもらったものに逆戻りしてるかもな」と言っています。
完全に迷子です。

これはAIが悪いというより、自分の側に開発やプロジェクト管理の知識がなく、出てきたものをとりあえず保存して進めていたことが大きいと思います。
普通に開発している人なら、ファイルの役割を整理し、変更履歴を管理し、どれが最新版なのかわかるようにするのでしょう。しかし、こちらは言われたコードを貼り付けて実行するだけで精一杯です。
便利なものは増えているのに、全体像はどんどん見えなくなっていきました。
ステムシートに収まらない
一方、出力側にも問題がありました。
ステムシートへ載せたい情報を増やしていくと、当然ながら紙面が足りなくなります。
ステムに貼れるサイズは限られています。そこへ1時間ごとの到達距離、到着予定時刻、補給、コンビニの有無、ルートの種類などを入れようとした結果、最初に出てきた表では文字が重なっていました。
Fuelが列からはみ出している。文字同士が重なって読めない。画面上で大きく表示すれば見えるものでも、ステムに貼るサイズまで縮めると使い物になりません。

そこで、表示する言葉を短くしていきました。
MountainはM、コンビニはCVS、水はWTR、ジェルはGEL、おにぎりはONI。
こうして、前回の記事に出てきた謎の記号だらけのステムシートが生まれました。
M350、ONI+GEL/WTR、CVS NO。

知らない人が見たら何の暗号かと思いますが、自分が見る分には問題ありません。むしろ走行中に確認するなら、長い説明より短い記号の方が読みやすい。
ただ、この作業を通して、情報を増やせば便利になるとは限らないことにも気づきました。
限られた場所へ載せるなら、何を追加するかと同じくらい、何を載せないかも大事です。
「ビジュアライゼーションを表示できません」
試作中には、よくわからない表示にも何度も遭遇しました。
「ビジュアライゼーションを表示できません」
ChatGPTがグラフや表を作ったようなのに、こちらでは表示できない。何かが出るはずなのに何も起こらず、処理だけが終了しているように見えることもありました。
さらに、画面に謎の「403r」のような文字が出て、これは何なんだ、という話にもなります。

プログラミングに慣れていれば、ログを読んだり、原因を切り分けたりするのでしょう。しかし、こちらから言えることは「何も起こらないんだけど」くらいです。
画面の状態や表示された文字をChatGPTへ伝え、必要なら出力されたテキストを貼り付け、修正案をもらってもう一度試す。
少し動いて、少し壊れて、また聞いて、また直す。その繰り返しでした。
AIに頼めば魔法のように一発で完成する、という感じではありません。かなり泥臭いですが、素人がAIに手伝ってもらいながら何かを作る実際のところは、たぶんこういうものなのだと思います。
それでも形にはなっていく
ファイルは増えました。出力も増えました。何が最新版なのかわからなくなることもありました。
それでも、少しずつ最初に欲しかったものへ近づいていきます。
GPXを読み込めば、距離と勾配から予測移動時間が出る。過去データをもとに、自分の勾配別速度を当てはめられる。休憩込みのグロス時間や補給の目安、1時間ごとの到達地点も出せるようになり、ステムシートとして印刷できる形も見えてきました。
自分ではコードを書けず、仕組みをすべて理解しているわけでもありません。それでも、「こうしたい」と伝え、結果を見て修正を頼むことを繰り返すと、少しずつ形になっていきます。
これはかなり面白い体験でした。
一方で、このまま整理せずに機能を増やし続ければ、どこかで完全に破綻することもわかってきました。
ここで一回整理しよう
チャットの中でも、僕はこう言っています。
「ちょっと色々スクリプトやらデータが湧いてきすぎちゃって、色々ごっちゃ混ぜになってきた。ここで一回整理しようよ」
まさに、その通りでした。
必要なものを残して、それ以外は削除する。どのスクリプトが何をするのか整理する。入力ファイルと出力ファイルを分け、最終的に使う流れを一本にする。

ここまで来ると、ChatGPTとの会話の中だけで試作を続けるのは、少し厳しくなってきます。
会話の中でコードを受け取り、手元で実行し、結果を貼って、また直してもらう。その方法でも進められますが、ファイルが増え、複数の機能が関係し始めると、だんだん管理しづらくなります。
特に、毎回スクリプトを個別に実行するのではなく、ルートを選べば必要な出力がまとめて作られる簡単なアプリにしたいと思い始めると、チャットだけで進めることには限界を感じました。
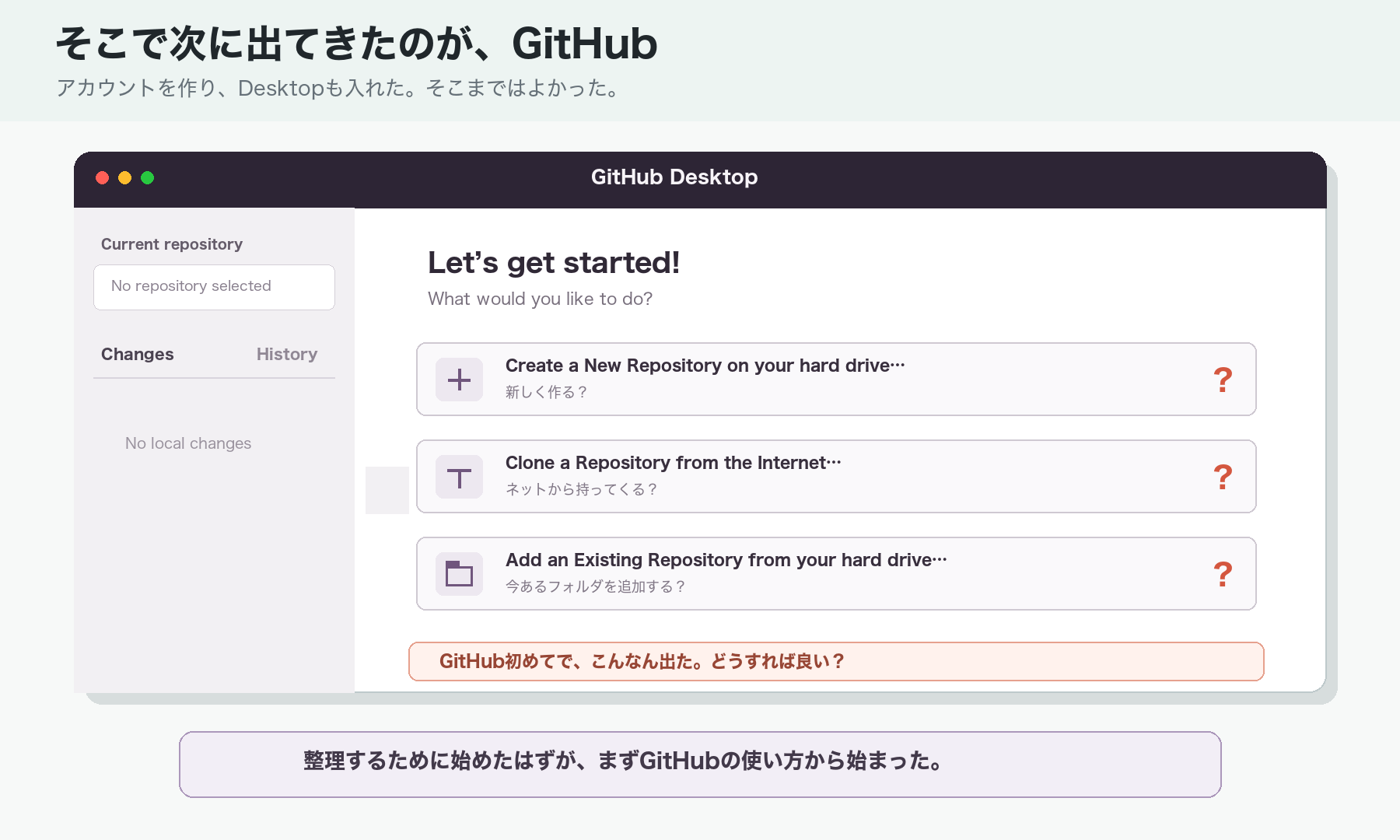
そこで次に出てくるのが、GitHubです。
ただし、僕はGitHubも初めてでした。アカウントを作り、GitHub Desktopも入れてみたものの、当然のようによくわからない画面が出ます。
どうすれば良い?
次回は、ChatGPTで作った試作品をいったん整理し、簡単なアプリの形にまとめながら、Codexを使った開発へ移っていく話です。
ここからようやく、「予測表を作る」から「実際に使えるツールにする」方向へ話が変わっていきます。
コメントを残す